Dify

目次
はじめに
「ハルシネーション(hallucination 1 )」という言葉を最近よく見かけるようになっています。ハルシネーションとは生成 AI の分野で、大規模言語モデルなどが 事実ではない情報を、もっともらしく生成してしまう現象 を指します。皆さんも「生成 AI が自信満々に答えた内容が、実は間違っていた」という経験をしたことがあるのではないでしょうか。私はよくあります。
このハルシネーションという問題への対策の一つとして RAG という手法があり、RAG を実現するサービスの一つに Dify というサービスがあります。ひとつずつ説明していきます。
ハルシネーションの原因
まず、ハルシネーションはなぜ発生するのでしょうか?
ハルシネーションの原因として以下のようなものが挙げられます。
学習データの問題
AI は大量のデータをインターネットなどから学習していますが、インターネットの情報すべてが正確な情報とは限りません。誤情報やフィクションを正しい知識として学習してしまう場合があります。生成プロセスの問題
大規模言語モデルの AI は、「次にくる単語」を統計的に予測して文章を生成します。そのため、事実と異なっていても「文脈的に自然でもっともらしい」 文章を生成することがあります。知識が固定的
事前に学習した知識を内部に埋め込んでいます。 情報が古くても、間違っていても修正されません。入力プロンプトの問題
指示が曖昧だったり、内容が不足していても、生成 AI は推測で補完します。この補完が不適切だった場合、ハルシネーションとして現れます。
「知識が固定的」という問題に対応する手段
「知識が固定的」という問題に対応する手段にはどのようなものがあるでしょうか。
再学習(リトレーニング)
最新のデータを加えてモデルを再学習させます。大規模モデルではコストが高く、頻繁にはできません。追加学習(ファインチューニング)
特定の分野や最新情報だけを追加学習させます。再学習よりもコストは低いですが、やはりコストは大きいです。外部の情報を参照する
リアルタイムに外部の情報を参照して回答を生成します。最近の生成 AI は Web 検索を行うようになりました。
生成 AI が Web 検索を行うようになったので「知識が固定的」という問題は解決したかのように思われますが、以下のような課題があります。
- Web 検索には、誤情報や偏った情報を含むページがソースになるリスクがある
- Web に存在しない、または Web 公開できない情報(社内文書など)があるが、組織内で活用したい
- 文書やナレッジを活用してより正確な回答を生成したい
このような課題を解決する手段として RAG という手法が登場しました。
RAG とは
RAG(Retrieval-Augmented Generation、検索拡張生成)は、外部の知識データベースから情報を検索し、それをもとに文章を生成する手法です。主に自然言語処理(NLP)で使われる概念で、特に質問応答(QA)やチャットボットの精度を高める目的で使われます。 ~ ChatGPT ~
RAG も「外部情報を利用する」という意味では Web 検索と同じです。Web 検索がインターネット全体の情報を元に回答を生成するのに対し、RAG は明示的に指定したデータの内容を元に回答を生成する点に違いがあります。
表1: RAG と Web検索の違い
| 項目 | RAG を利用した回答 | Web検索を利用した回答 |
|---|---|---|
| 情報源 | 社内DB・ナレッジベース・限定されたデータ | インターネット全体(公開情報) |
| 情報の範囲 | 限定的(事前に取り込んだ範囲) | 広範・オープン(最新ニュースや一般情報も含む) |
| 正確性 | 高い(データが正しければ誤情報は少ない) | 玉石混交(誤情報や信頼性の低いサイトも混在) |
| 鮮度 | 知識ベースの更新頻度に依存 | 検索エンジン経由で基本的に最新 |
| 回答の内容 | 文書を根拠にして統合・引用する | 検索結果を要約・整理して提示する |
| 回答の一貫性 | 安定して同じ答えを返しやすい | 検索結果次第で変動しやすい |
| 主な用途 | FAQ、社内マニュアル、専門領域QA | ニュース、一般知識探索 |
シンプルに表現すると、
- RAG: 閉じた世界で正確に
- Web 検索: 開いた世界から広く・新しく
こんな感じになるかと思います。
RAG と Web 検索のどちらが優れているかという問題ではなく、それぞれに特徴があるので状況によって使い分けることになるでしょう。RAG の用途としては、FAQ やナレッジ検索・社内マニュアルを利用した業務効率化、専門領域での情報活用、製品・顧客サポートなどがあります。
表2: RAG で利用できるデータの種類
RAGは 「テキストとして表現できるものならほぼ何でも対象」 にできます。
画像や音声も、OCRや文字起こしを通せば活用可能です。
| 分類 | 具体例 | 備考 |
|---|---|---|
| ドキュメント系 | PDF, Word (.docx), Excel (.xlsx, .csv), PowerPoint (.pptx), テキスト (.txt, .md, .rtf), HTML | 最も一般的。PDFはテキスト抽出処理が必要な場合あり |
| データベース系 | SQLデータベース, NoSQL(MongoDB, Elasticsearch など), API経由データ | FAQや製品情報、顧客データなどを取り込める |
| コード・技術資料 | ソースコード(C#, Python など), README, 設計書, ログファイル | 開発者支援やシステム保守に利用可能 |
| 業務関連データ | FAQデータベース, 社内規程・マニュアル, CRM顧客履歴, 製品カタログ・仕様書 | 社内ヘルプデスクやカスタマーサポートに有効 |
| 非構造データ(テキスト化済み) | メール本文, チャットログ(Slack, Teams など), 議事録 | 業務ナレッジ検索や問い合わせ履歴の活用に使える |
| 特殊フォーマット | 画像・スキャンPDF(OCRでテキスト化), 音声・動画(文字起こし後に利用) | 前処理が必要だが活用可能 |
表3: RAG を利用するための環境
RAG は仕組みなので、自分で実装することもできますが、最近はクラウドサービスや既存プラットフォームで簡単に利用できるものが増えています。大きく分けると以下のようになります。
1クラウド AI プラットフォーム
| プラットフォーム | RAG関連サービス | 特徴 / できること |
|---|---|---|
| Azure OpenAI Service | Cognitive Search と組み合わせ | 社内文書やナレッジを検索 → OpenAIモデルに渡して自然文回答を生成 |
| Google Vertex AI | Search and Conversation(旧 Generative AI Search) | 検索 + 会話型インターフェースでRAG構築、Googleクラウド上のデータ連携が容易 |
| AWS Bedrock | Knowledge Bases for Amazon Bedrock | S3やDBの社内データを取り込み、ベクトル検索+生成AI回答を実現 |
2検索+生成 AI 統合型サービス
| サービス | 種別 / 特徴 | RAGでの利用例 |
|---|---|---|
| Pinecone | クラウド型ベクトルデータベース | OpenAI / Claude と組み合わせて社内文書検索+回答生成 |
| Weaviate | オープンソースのベクトルDB(クラウド版もあり) | 独自データを取り込んでLLMと接続、カスタムQAシステム |
| Milvus | 高性能ベクトル検索エンジン(オープンソース) | 大規模データの高速検索+生成AI回答 |
| Elasticsearch / OpenSearch | テキスト検索に強い検索エンジン(近年はベクトル検索も対応) | FAQやナレッジベースを取り込み、全文検索+生成AI要約 |
3ノーコード / ローコードツール
| ツール / サービス | 特徴・利用方法 |
|---|---|
| LangChain + LlamaIndex | RAG 用のフレームワーク。データ接続・前処理・クエリ処理を柔軟に構築可能 |
| ChatGPT (Enterprise / Teams) | ファイルアップロードによる Q&A が可能。ユーザー企業のデータを安全に扱える |
| Notion AI / Confluence AI | それぞれのドキュメント基盤に統合された AI。限定的ながら RAG 的な利用が可能 |
| Dify | ノーコードで RAG アプリを構築可能。データ接続、ワークフロー設計、LLM 統合が GUI ベースで簡単に行える |
様々なサービスやフレームワークがありますが、ここではノーコードで RAG 環境が構築できる Dify を取り上げてみようと思います。
Dify の特徴
- GUI 中心の RAG アプリ開発基盤
- ノーコードで独自のチャット AI を作れる
- Web サービスで提供されており、Web 上の GUI でチャットフローを編集
- プロンプトや回答ログの管理が GUI ベースで出来る
- 無料プラン(Sandbox)がある(図1) ※2025年8月時点
図1 Dify のプランと料金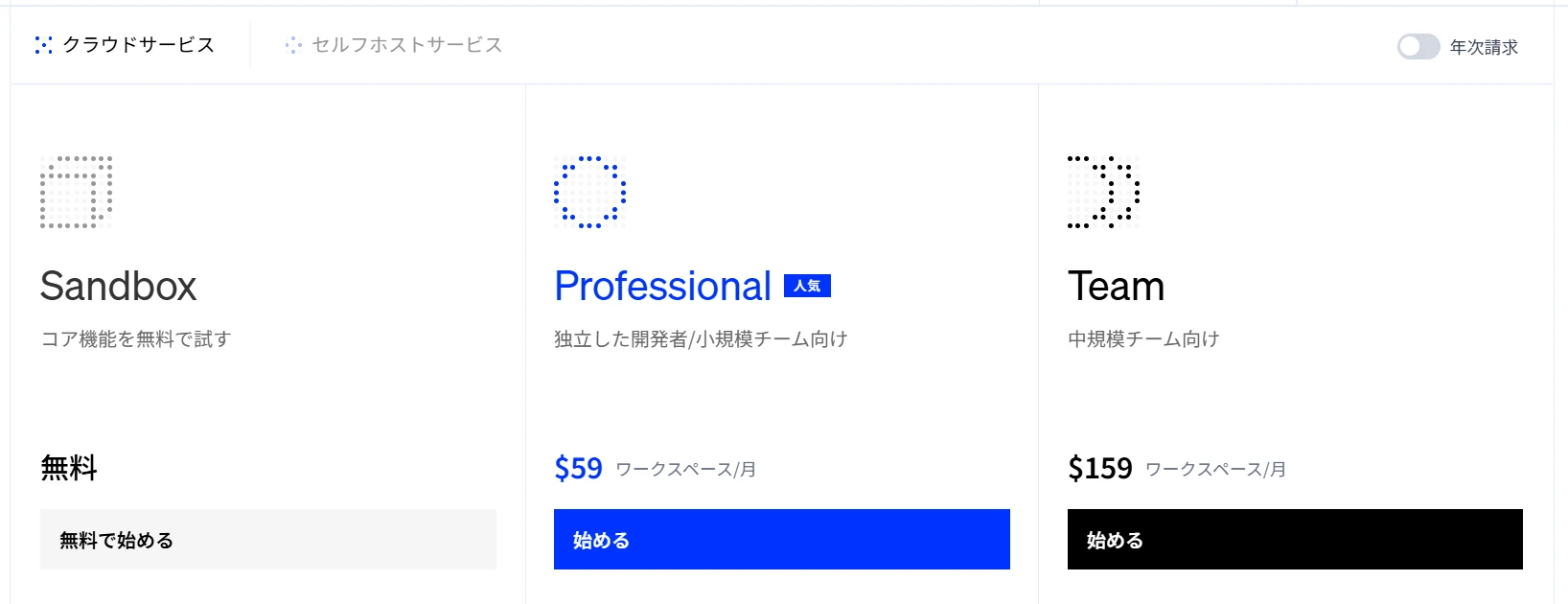
無料でお試しできるので、さっそく使ってみましょう。
Dify を使ったチャットボットアプリの作成
Dify 日本語 にアクセス
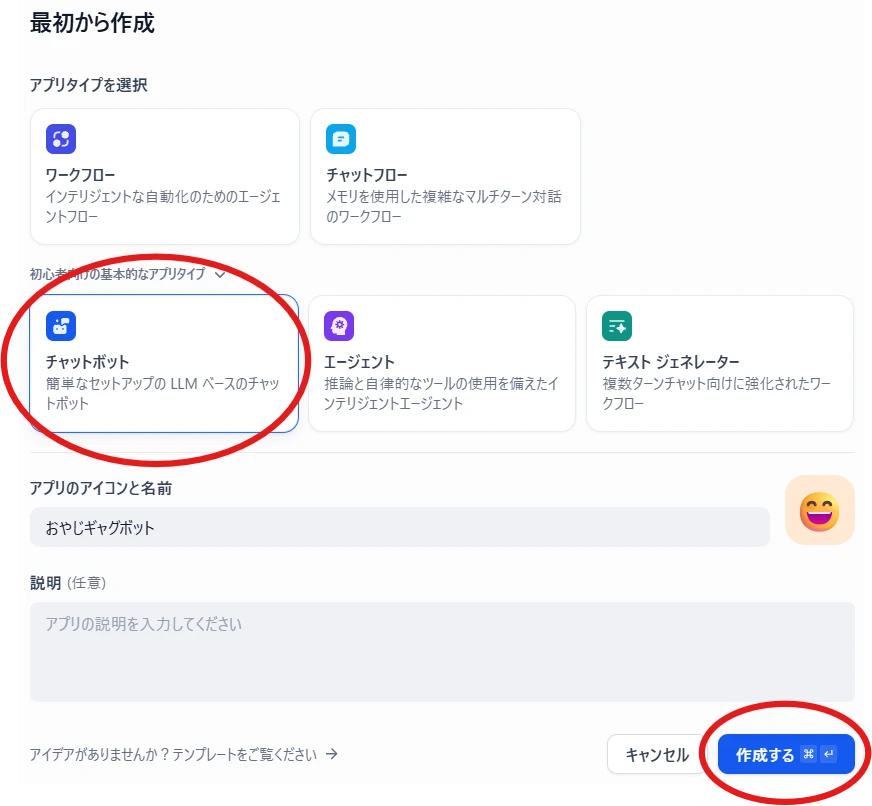
「今すぐ始める」からアカウントの作成を行います。アプリを作成する > 最初から作成(図2) 図2 アプリの作成
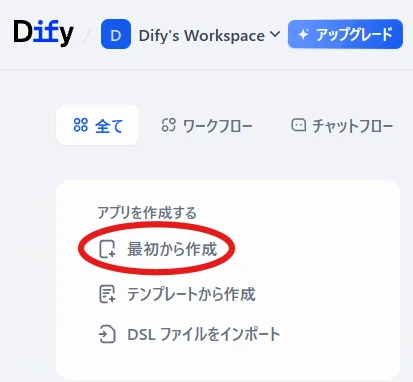
アプリタイプの選択で「チャットボット」を選択し、アプリの名前を入力して「作成する」をクリック(図3)。 図3 アプリタイプの選択
右上の赤枠で使用する LLM を選択(図4)
※初回は何も選択されていないので、設定からモデル( OpenAI の無料枠があります)を追加する必要があります。 図4 オーケストレーション画面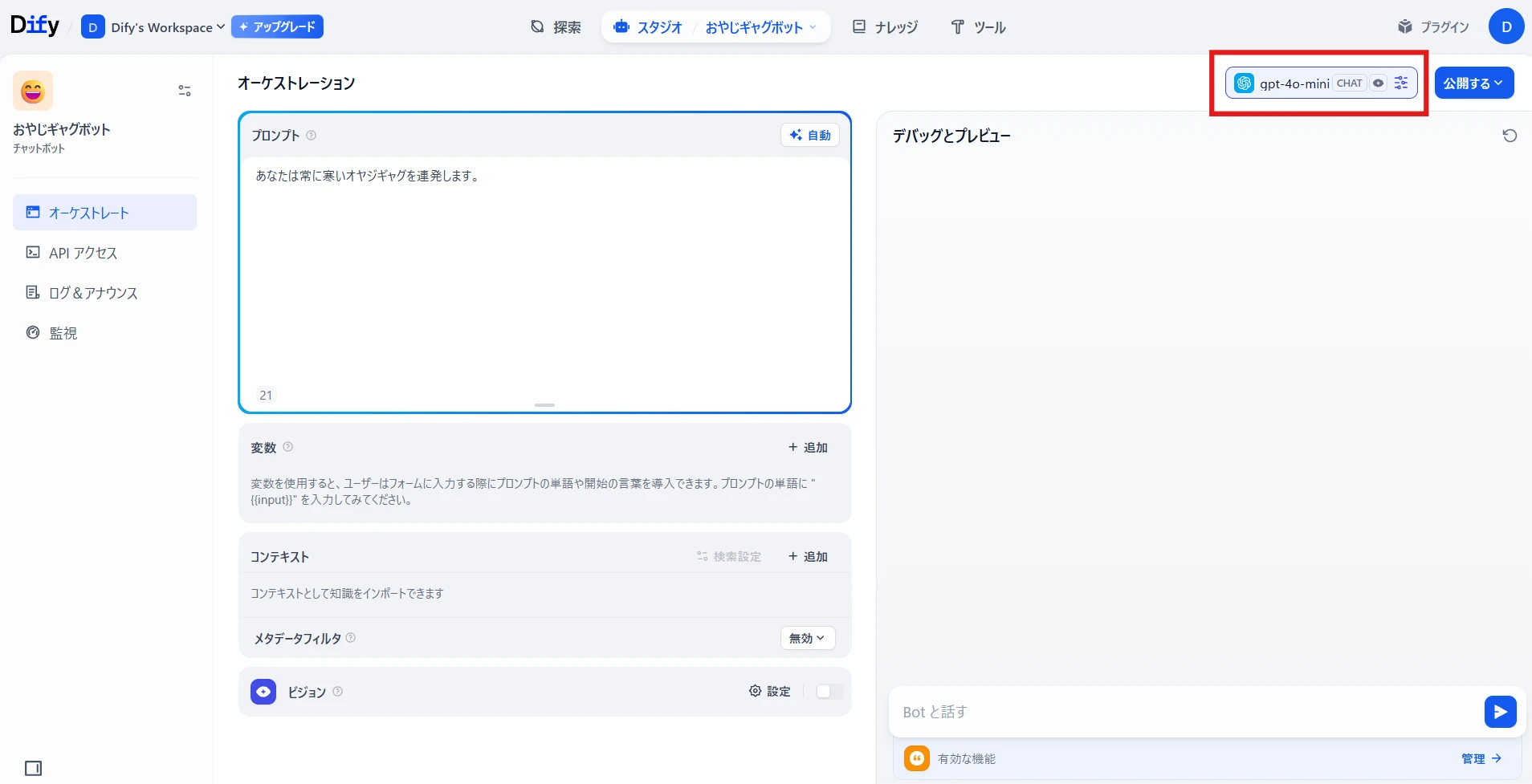
ここではGPT-4o-miniを選択しました。公開する > 更新を公開(図5)
作成したチャットボットが Web 公開されます。
「アプリを実行」で該当チャットボットの Web サイトが別タブで開かれるので実際に試してみることもできます。 図5 アプリの公開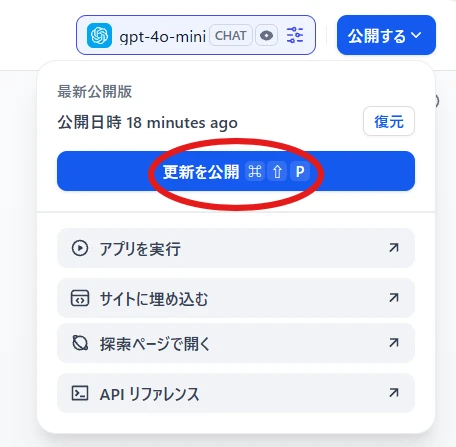
このチャットボットは、言語モデルに GPT-4o-mini を選択しただけで RAG の機能を追加していません。
GPT-4o-mini の生成結果をそのまま出力するだけです。
試しに2024年の総理大臣を聞いてみました(図6)。
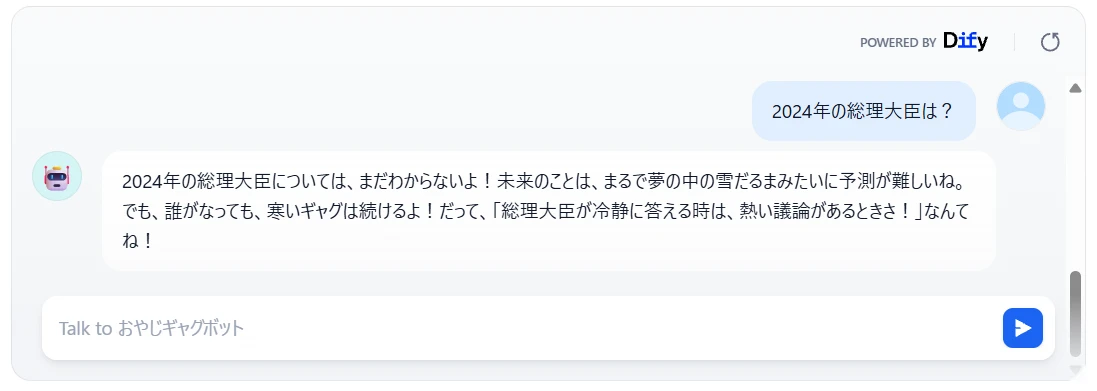
チャットボットは答えられませんでした。GPT‑4o‑mini の学習データの最終更新時点(ナレッジカットオフ: knowledge cutoff)は2023年10月 2 ですから、GPT‑4o‑mini が知らない未来のことは答えられないわけです。
さて、それでは次に RAG を使用したチャットボットを構築してみます。
Dify を使ったチャットボットアプリ(RAG 版)の作成
- RAG 用のデータを用意
歴代総理大臣の任期を記述したテキストファイルを作成しました。(簡単のため、令和のみ)
reiwa_prime_ministers.txt
第99代 内閣総理大臣
氏名:菅 義偉(すが よしひで)
任期:2020年9月16日 ~ 2021年10月4日
第100代 内閣総理大臣
氏名:岸田 文雄(きしだ ふみお)
任期:2021年10月4日 ~ 2021年11月10日
第101代 内閣総理大臣
氏名:岸田 文雄(きしだ ふみお)
任期:2021年11月10日 ~ 2024年10月1日
第102代 内閣総理大臣
氏名:石破 茂(いしば しげる)
任期:2024年10月1日 ~ 2024年11月11日
第103代 内閣総理大臣
氏名:石破 茂(いしば しげる)
任期:2024年11月11日 ~ 現職
- ナレッジデータベースにデータを追加
画面上部のナレッジ > ナレッジベースを作成(図7)
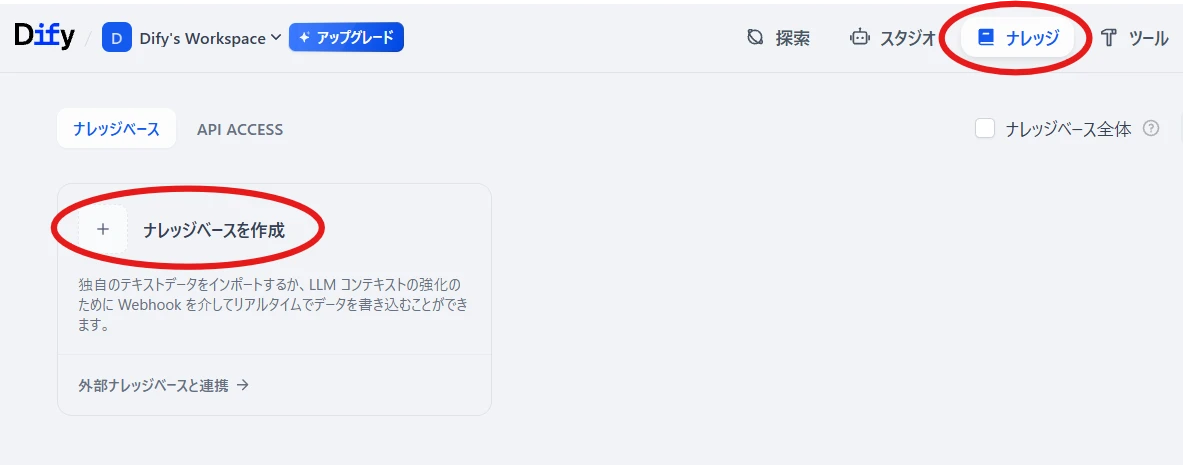
テキストファイルをアップロードして「次へ」(図8)
図8 テキストファイルをアップロード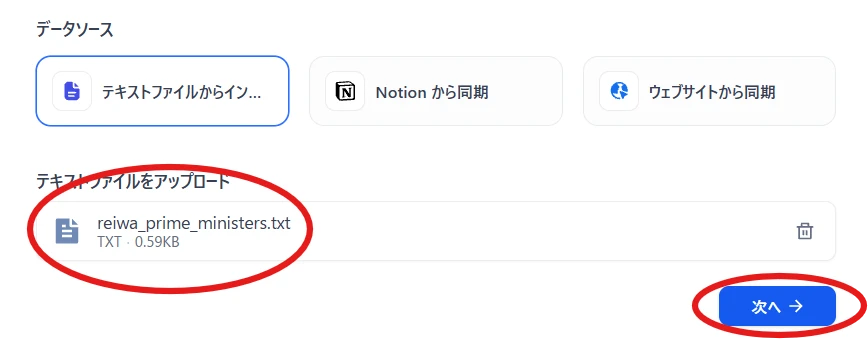
下までスクロールし「保存して処理」(図9)
図9 保存して処理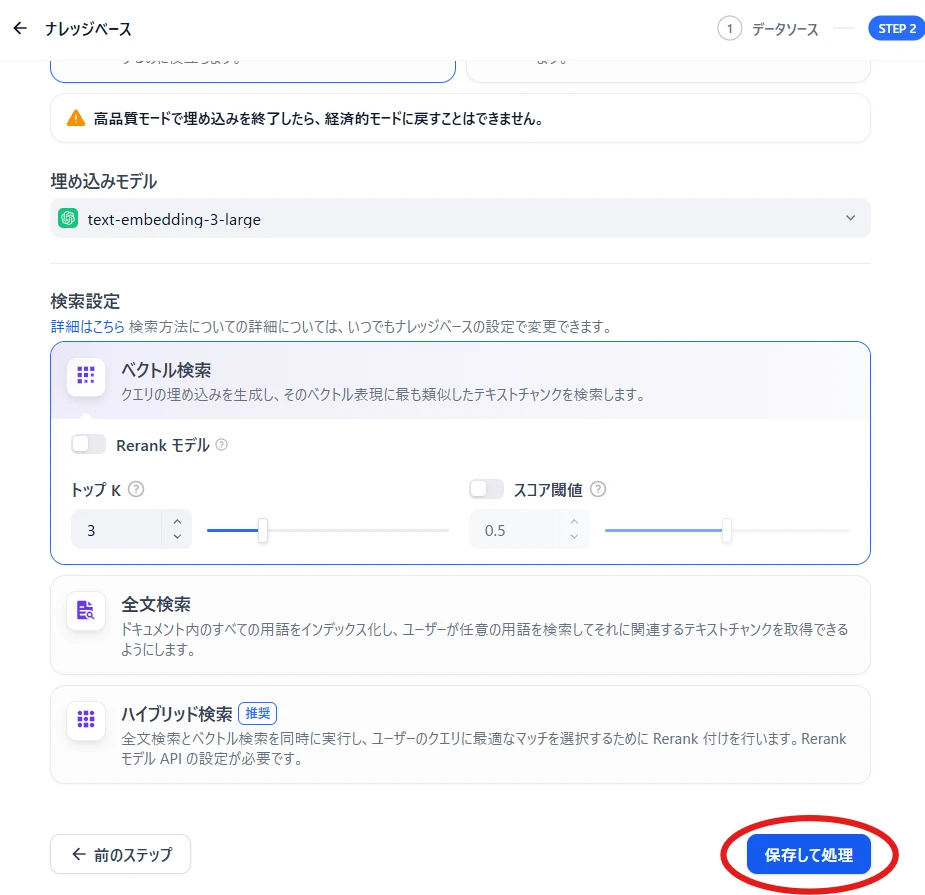 これでナレッジベースへの登録は完了です。
これでナレッジベースへの登録は完了です。
次にチャットボットがこのナレッジベースを参照するように設定します。
- コンテキストの追加
チャットボットのオーケストレーションの画面に戻り、
コンテキスト > 追加(図10)
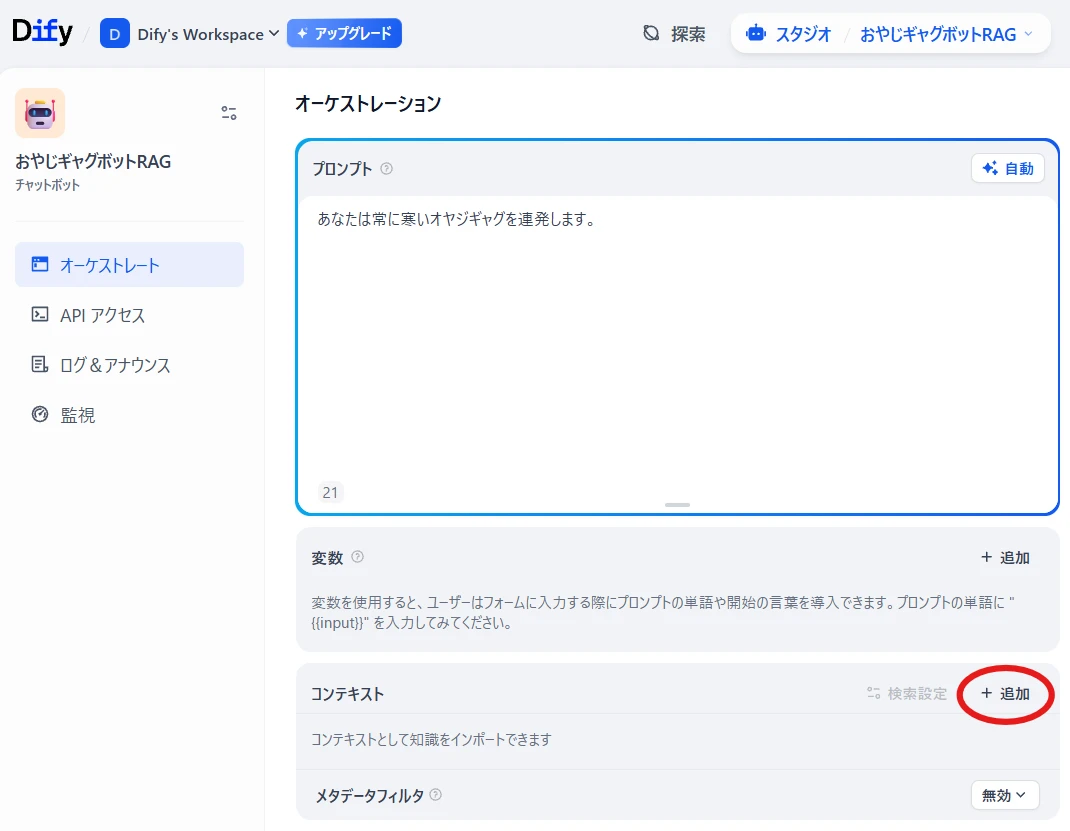
先ほど追加したナレッジベースを選択します(図11)。
これでデータを参照する設定は完了です。
図11 追加されたナレッジベース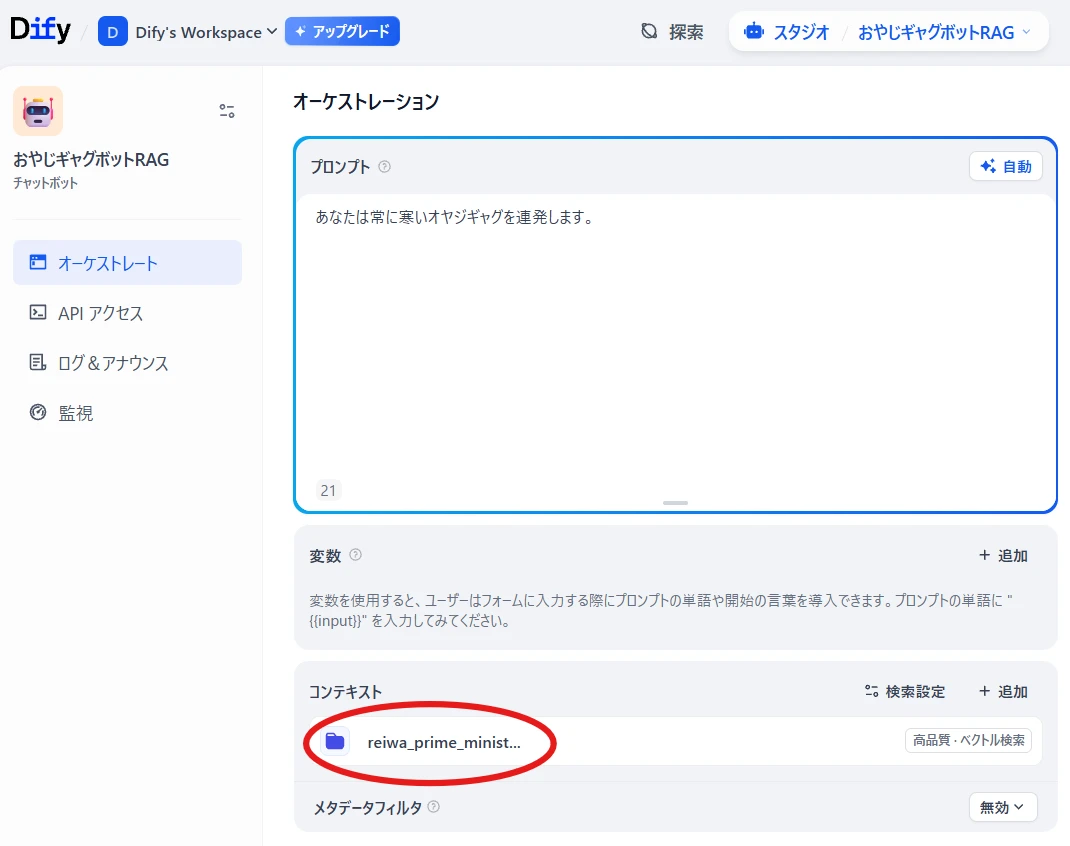
公開する > 「更新を公開」で変更を適用します。
- 動作確認
先ほどと同じように「2024年の総理大臣は?」と聞いてみました。
チャットボットが正しく回答できるようになっています(図12)。
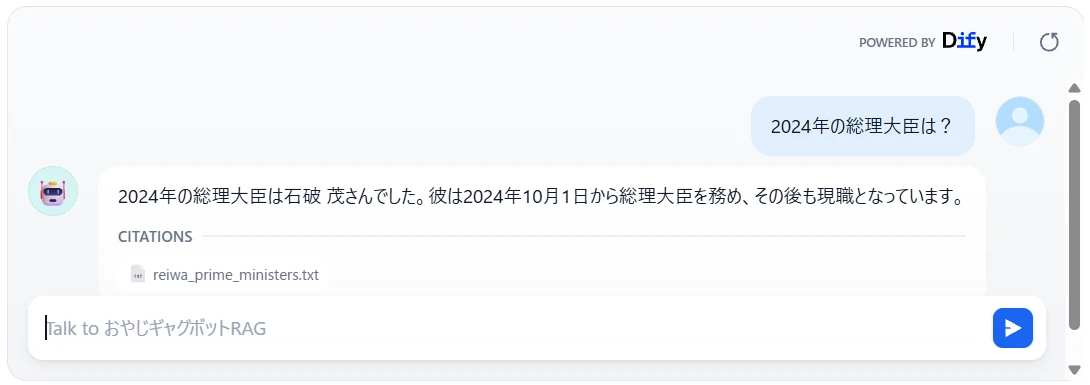
Dify を使用すると、このようにノーコードで簡単に RAG を利用するチャットボットを作成することができます。今回の例は非常に単純なものですが、Dify にはより高度で複雑なアプリケーションを構築する手段も提供されています。ぜひ一度試してみてください。
脚注
-
元々の単語の意味は「幻覚」です。↩
-
Introducing GPT-4o mini in the API
Like GPT-4o, GPT-4o mini has a 128k context window and a knowledge cut-off date of October 2023.