Dify

Table of Contents
Introduction
The term "hallucination 1" has become increasingly common recently. In the field of generative AI, hallucination refers to the phenomenon where large language models generate information that is not factual but appears plausible. I'm sure many of you have experienced generative AI confidently providing an answer that was actually incorrect. I certainly have, quite often.
One of the countermeasures for this hallucination problem is a technique called RAG, and Dify is one of the services that implements RAG. I will explain each of these step-by-step.
Causes of Hallucination
First, why do hallucinations occur?
The following are some of the causes of hallucination:
Learning Data Issues
AI learns from vast amounts of data, often from the internet, but not all information on the internet is accurate. It may learn misinformation or fiction as correct knowledge.Generation Process Issues
Large language models generate text by statistically predicting the "next word." Consequently, they may generate sentences that are "contextually natural and plausible," even if they are factually incorrect.Fixed Knowledge
They embed pre-learned knowledge internally. Information is not updated even if it becomes old or incorrect.Input Prompt Issues
Even if instructions are ambiguous or content is insufficient, generative AI will make assumptions to complete the information. If this completion is inappropriate, it manifests as a hallucination.
Means to Address the "Fixed Knowledge" Problem
What are the ways to address the "fixed knowledge" problem?
Retraining
Retrain the model by adding the latest data. This is costly for large models and cannot be done frequently.Additional Learning (Fine-tuning)
Add learning for specific domains or the latest information only. This is less costly than retraining, but still involves significant expense.Referencing External Information
Generate answers by referencing external information in real-time. Recent generative AIs have started performing web searches.
Although it might seem that the "fixed knowledge" problem has been resolved now that generative AI performs web searches, there are still challenges such as the following:
- Web searches carry the risk of sourcing pages that contain misinformation or biased information.
- There is information that does not exist on the web or cannot be published on the web (e.g., internal company documents) that organizations wish to utilize internally.
- The desire to generate more accurate answers by leveraging documents and knowledge bases.
To solve these challenges, the RAG technique emerged.
What is RAG?
RAG (Retrieval-Augmented Generation) is a technique that retrieves information from an external knowledge database and generates text based on it. It is primarily a concept used in Natural Language Processing (NLP), especially for the purpose of improving the accuracy of question answering (QA) and chatbots. ~ ChatGPT ~
RAG is similar to web search in that it "uses external information." The difference is that while web search generates answers based on information from the entire internet, RAG generates answers based on the content of explicitly specified data.
Table 1: Differences between RAG and Web Search
| Item | Answers using RAG | Answers using Web Search |
|---|---|---|
| Information Source | Internal DB, knowledge base, limited data | Entire internet (public information) |
| Scope of Information | Limited (pre-ingested scope) | Broad/Open (includes latest news and general information) |
| Accuracy | High (fewer errors if data is correct) | Mixed (misinformation and unreliable sites also present) |
| Freshness | Depends on knowledge base update frequency | Generally up-to-date via search engine |
| Content of Answer | Integrates/quotes based on documents | Summarizes/organizes search results and presents them |
| Consistency of Answer | Tends to return the same answer consistently | Prone to variation depending on search results |
| Main Uses | FAQ, internal manuals, specialized domain QA | News, general knowledge exploration |
Simply put,
- RAG: Accurate in a closed world
- Web Search: Broad and new from an open world
This is how it can be summarized.
It's not a question of whether RAG or web search is superior; rather, each has its own characteristics, so they will be used differently depending on the situation. RAG applications include FAQs, knowledge search, business efficiency improvements using internal manuals, information utilization in specialized domains, and product/customer support.
Table 2: Types of Data Usable with RAG
RAG can target "almost anything that can be expressed as text."
Even images and audio can be utilized after passing through OCR or transcription.
| Category | Examples | Notes |
|---|---|---|
| Document-based | PDF, Word (.docx), Excel (.xlsx, .csv), PowerPoint (.pptx), Text (.txt, .md, .rtf), HTML | Most common. PDFs may require text extraction processing. |
| Database-based | SQL databases, NoSQL (MongoDB, Elasticsearch, etc.), API-accessed data | Can ingest FAQs, product information, customer data, etc. |
| Code/Technical Documentation | Source code (C#, Python, etc.), READMEs, design documents, log files | Can be used for developer support and system maintenance |
| Business-related Data | FAQ databases, internal regulations/manuals, CRM customer history, product catalogs/specifications | Effective for internal help desks and customer support |
| Unstructured Data (Textualized) | Email bodies, chat logs (Slack, Teams, etc.), meeting minutes | Can be used for business knowledge search and utilizing inquiry history |
| Special Formats | Images/Scanned PDFs (textualized with OCR), Audio/Video (used after transcription) | Requires pre-processing but usable |
Table 3: Environments for Utilizing RAG
Since RAG is a mechanism, you can implement it yourself, but recently, more cloud services and existing platforms make it easy to use. Broadly, they can be categorized as follows:
1Cloud AI Platforms
| Platform | RAG-related Services | Features / Capabilities |
|---|---|---|
| Azure OpenAI Service | Combined with Cognitive Search | Search internal documents and knowledge → Pass to OpenAI model to generate natural language answers |
| Google Vertex AI | Search and Conversation (formerly Generative AI Search) | RAG construction with search + conversational interface, easy data integration on Google Cloud |
| AWS Bedrock | Knowledge Bases for Amazon Bedrock | Ingest internal data from S3 and databases, achieve vector search + generative AI answers |
2Search + Generative AI Integrated Services
| Service | Type / Features | RAG Use Case |
|---|---|---|
| Pinecone | Cloud-based vector database | Combine with OpenAI / Claude for internal document search + answer generation |
| Weaviate | Open-source vector DB (cloud version also available) | Ingest custom data, connect with LLM, create custom QA systems |
| Milvus | High-performance vector search engine (open source) | High-speed search of large-scale data + generative AI answers |
| Elasticsearch / OpenSearch | Search engine strong in text search (recently supports vector search) | Ingest FAQs and knowledge bases, full-text search + generative AI summarization |
3No-code / Low-code Tools
| Tool / Service | Features / Usage |
|---|---|
| LangChain + LlamaIndex | Framework for RAG. Allows flexible construction of data connection, pre-processing, and query processing |
| ChatGPT (Enterprise / Teams) | Enables Q&A via file upload. Can securely handle user company data |
| Notion AI / Confluence AI | AI integrated into their respective document platforms. Enables RAG-like usage, though limited |
| Dify | Enables building RAG apps with no code. Data connection, workflow design, and LLM integration can be easily done via a GUI |
While there are various services and frameworks, here I will focus on Dify, which allows building a RAG environment with no code.
Dify's Features
- GUI-centric RAG application development platform
- Create your own chat AI with no code
- Provided as a web service, with chat flow editing via a web-based GUI
- Prompt and response log management can be done via a GUI
- Has a free plan (Sandbox) (Figure 1.) *As of August 2025
Figure 1. Dify plans and pricing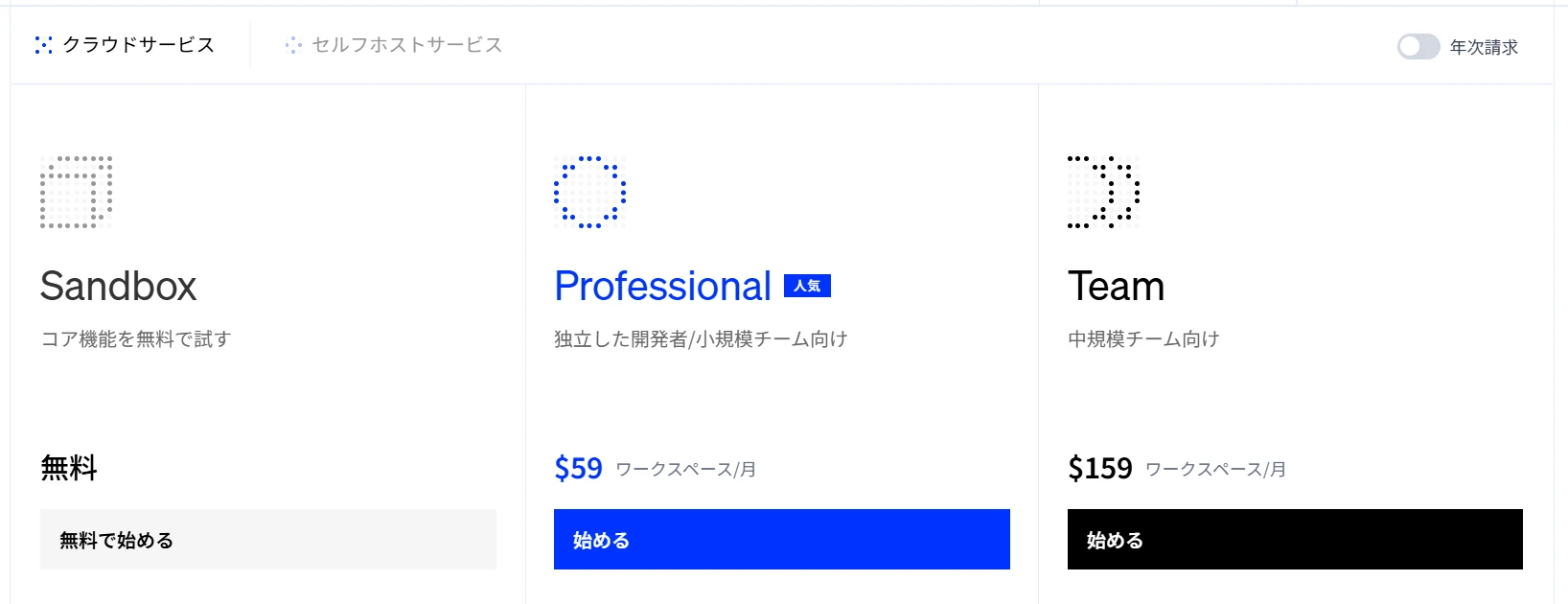
Since you can try it for free, let's start using it right away.
Creating a Chatbot App Using Dify
Access Dify Japanese
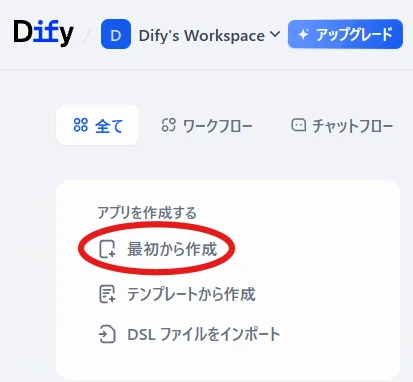
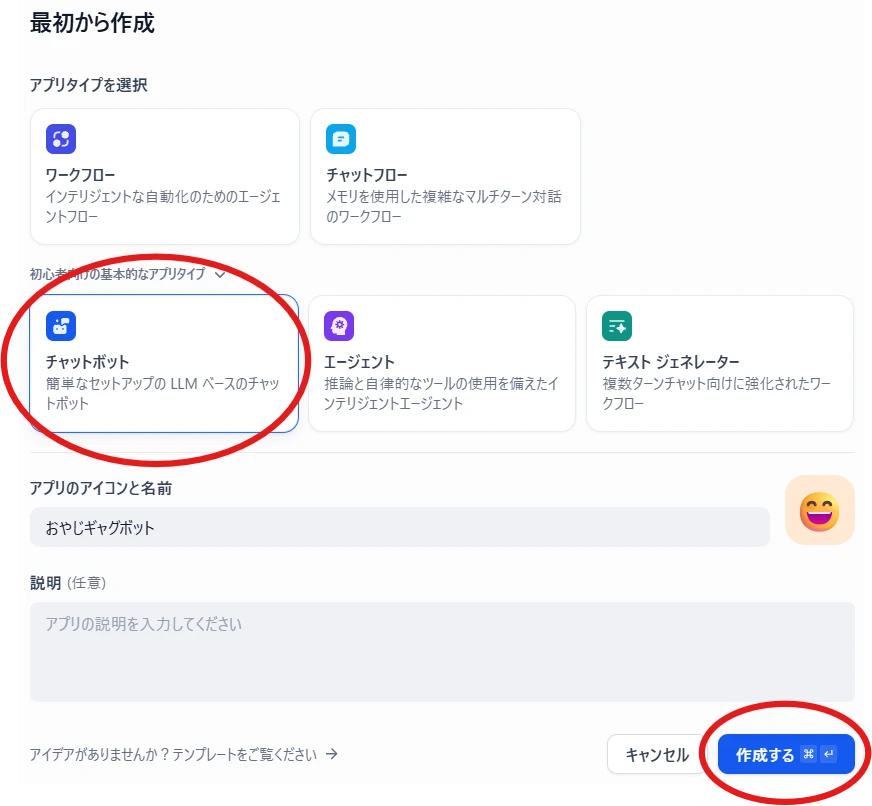
Create an account from "Get Started Now."Create an app > Create from scratch (Figure 2.) Figure 2. Creating an app
Select "Chatbot" for app type, enter the app name, and click "Create" (Figure 3.). Figure 3. Selecting the app type
Select the LLM to use in the red box at the top right (Figure 4.)
*Initially, nothing is selected, so you'll need to add a model (there's a free tier for OpenAI) from the settings. Figure 4. Orchestration screen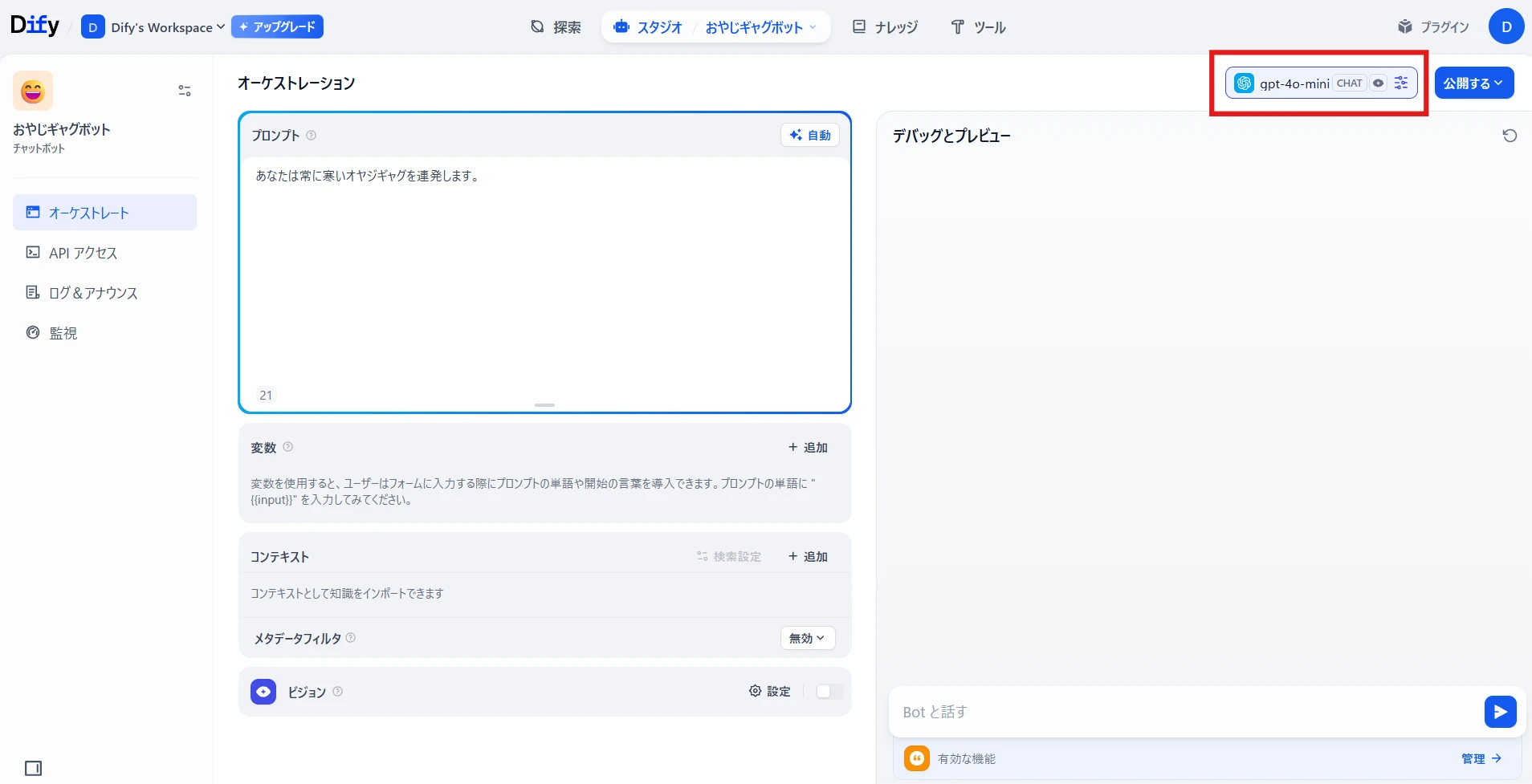
Here, I selectedGPT-4o-mini.Publish > Publish Update (Figure 5.)
The created chatbot will be published to the web.
You can try it out by clicking "Run App," which opens the chatbot's website in a new tab. Figure 5. App publishing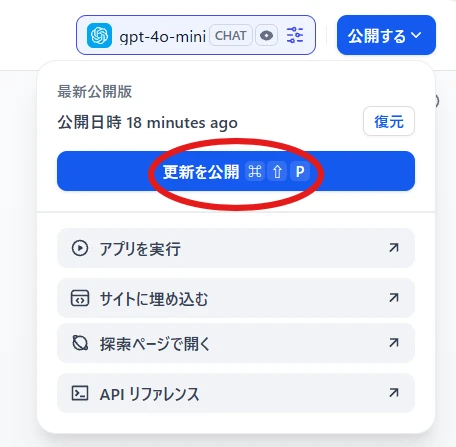
This chatbot only selected GPT-4o-mini as the language model and does not have RAG functionality added.
It simply outputs the generation result of GPT-4o-mini as is.
I tried asking about the Prime Minister in 2024 (Figure 6.).
Figure 6. Who is the Prime Minister in 2024?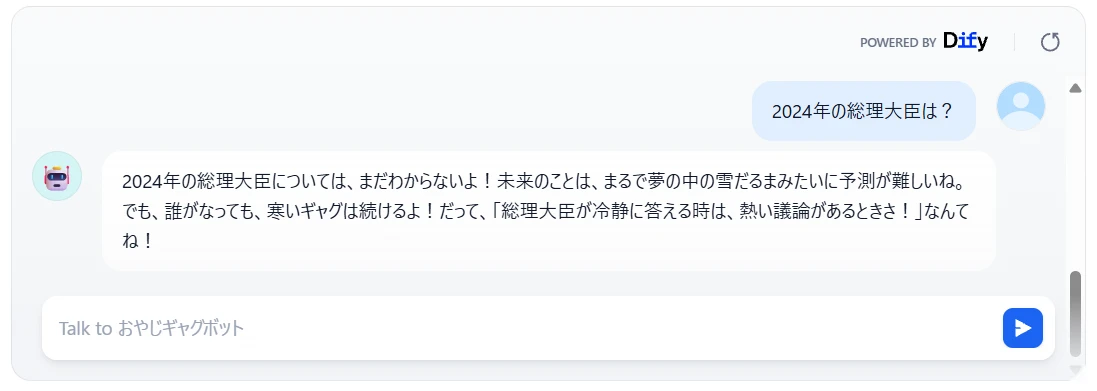
The chatbot could not answer. Since GPT‑4o‑mini's knowledge cut-off date for its training data is October 2023 2, GPT‑4o‑mini cannot answer questions about a future it doesn't know.
Now, let's try building a chatbot that uses RAG.
Creating a Chatbot App Using Dify (RAG Version)
- Prepare data for RAG
I created a text file describing the terms of past Prime Ministers (Reiwa era only, for simplicity).
reiwa_prime_ministers.txt
99th Prime Minister
Name: Yoshihide Suga
Term: September 16, 2020 – October 4, 2021
100th Prime Minister
Name: Fumio Kishida
Term: October 4, 2021 – November 10, 2021
101st Prime Minister
Name: Fumio Kishida
Term: November 10, 2021 – October 1, 2024
102nd Prime Minister
Name: Shigeru Ishiba
Term: October 1, 2024 – November 11, 2024
103rd Prime Minister
Name: Shigeru Ishiba
Term: November 11, 2024 – Incumbent
- Add data to the knowledge database
Knowledge at the top of the screen > Create Knowledge Base (Figure 7.)
Figure 7. Create Knowledge Base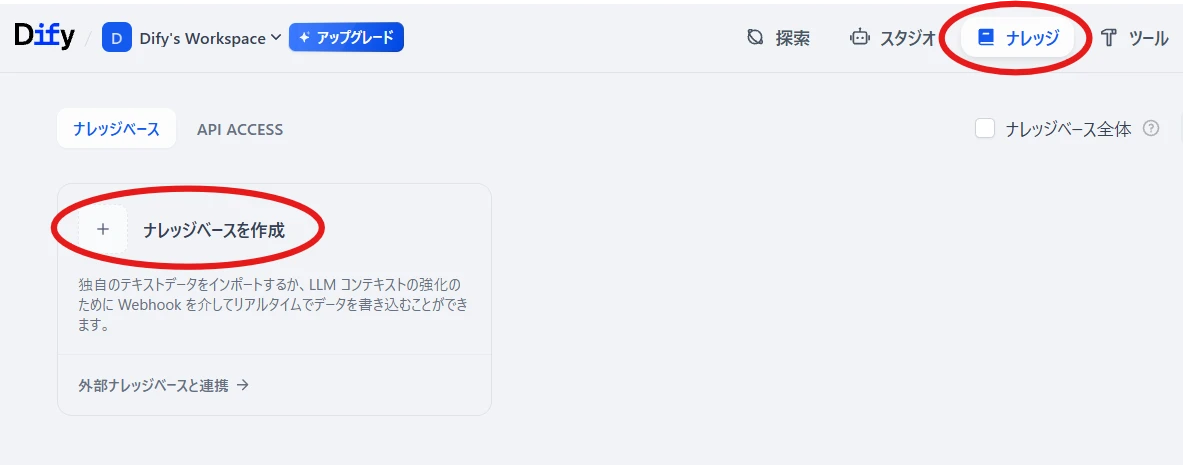
Upload the text file and click "Next" (Figure 8.)
Figure 8. Upload text file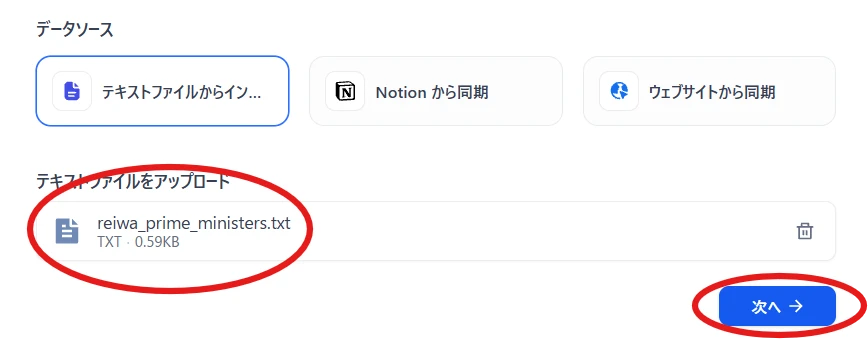
Scroll down and click "Save and Process" (Figure 9.)
Figure 9. Save and Process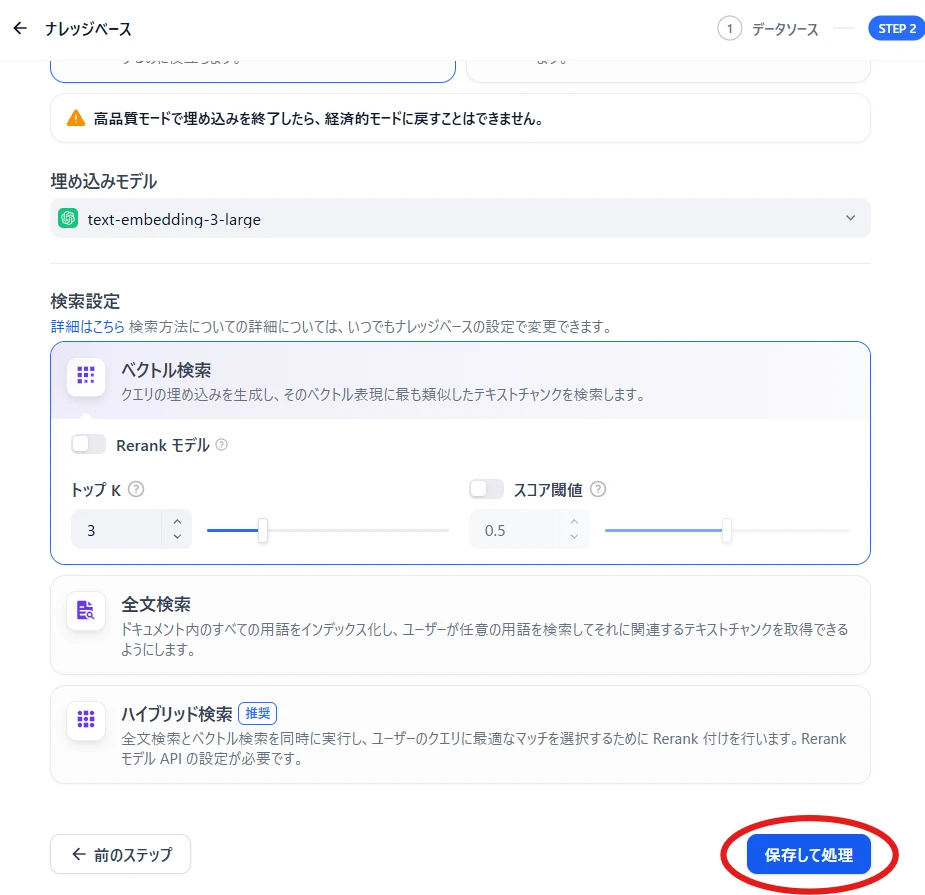 This completes the registration to the knowledge base.
This completes the registration to the knowledge base.
Next, we will configure the chatbot to refer to this knowledge base.
- Add Context
Return to the chatbot's orchestration screen, and
Context > Add (Figure 10.)
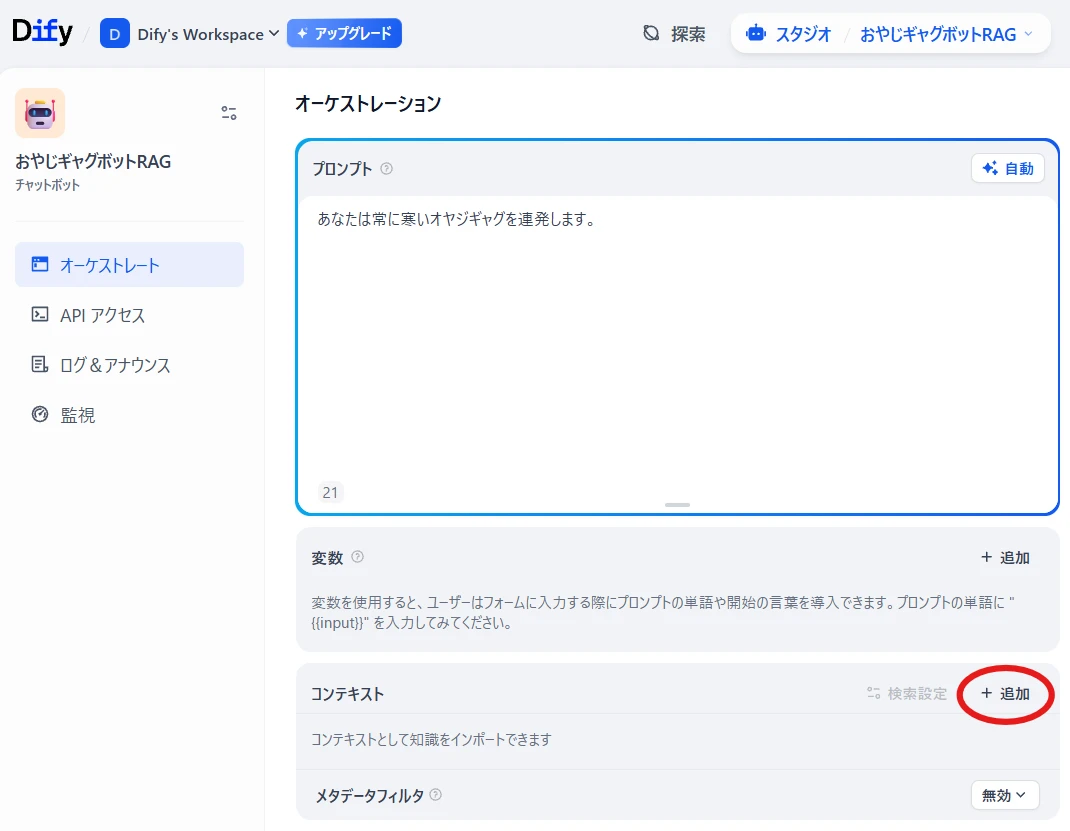
Select the knowledge base you just added (Figure 11.).
This completes the setting for referencing the data.
Figure 11. Added knowledge base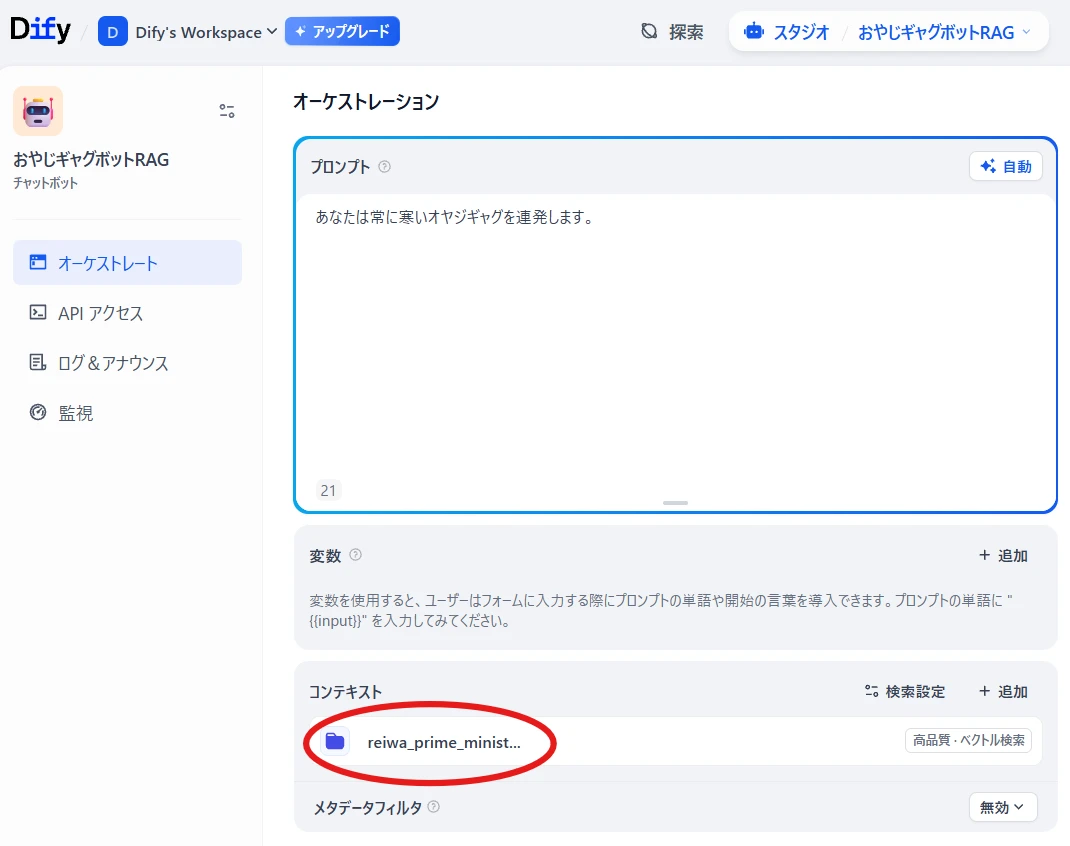
Publish > Apply changes with "Publish Update."
- Operation Confirmation
I asked "Who is the Prime Minister in 2024?" just as before.
The chatbot is now able to answer correctly (Figure 12.).
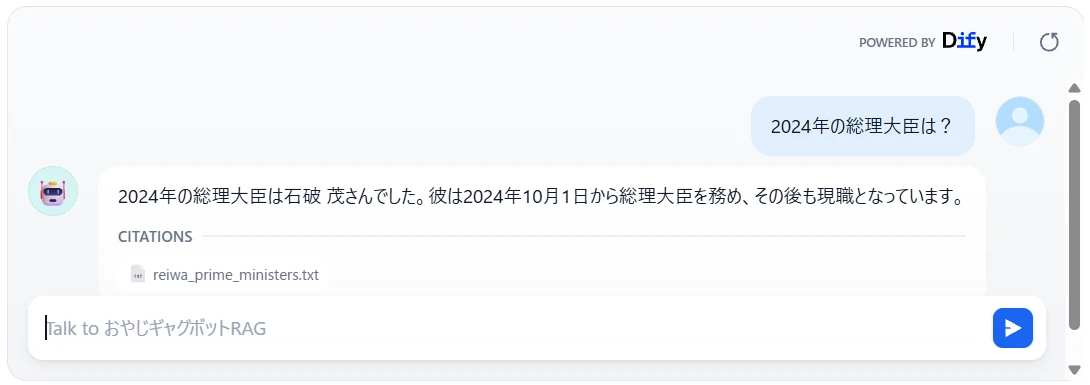
By using Dify, you can easily create a chatbot that utilizes RAG with no code, as shown. While this example is very simple, Dify also provides means to build more advanced and complex applications. Please give it a try.
Footnotes
-
The original meaning of the word is "hallucination."↩
-
Introducing GPT-4o mini in the API
Like GPT-4o, GPT-4o mini has a 128k context window and a knowledge cut-off date of October 2023.